
As part of a project I’m working on for fun (shhhh) I’ve been trying to solve an interesting problem – what is the most compact way I can uniquely refer to something in a URI?
This one’s going to get complicated, so here’s the tl;dr version. To get the shortest possible, web-safe identifiers:
- encode identifiers with base62 or a customized version of base64 that uses valid characters.
- Use a big enough hash space to get an acceptable level of collisions.
Ok. Here’s the long-winded version.
It’s a little like the “URL Shortener” use case, where you want to take a big fat link and describe it in a tiny link. In this case, I’m converting individual sentences into a tiny, linkable representation.
So, I need a very short identifier that obeys certain (conflicting) properties:
- As much as possible, the identifier should be the same regardless of the order that I create the sentences in
- It should be as short as possible, because I may need to refer to a lot of these in a single URI
In the URL shortener mode, they tend to solve this by just keeping a global “ID” counter and incrementing it every time someone creates a new link. I need to use something a lot more like a hash. (MD5 or SHA1 are typical choices here.)
So what are the constraints?
- How long can a URI be?
- What characters are we allowed to use?
- How much unique data is going to be represented?
- How tolerant can we be of collisions? (When 2 “objects” might map to the same shortened identifier?)
URI constraints
The first 2 are simple and global. There’s no real standard on URI length, but smart people have done the legwork for us so we’ll steal their conclusions, and say “keep URI’s shorter than 2,000 characters.”
As far as the characters that can be used, we can consult RFC 3986 in the “Unreserved Characters” section and find we’re allowed 0-9, a-z, A-Z, and “- _ . ~” (dash, underscore, dot, tilde.) I’m going to avoid using those because I’d like to keep them for separating my identifiers. So, if we just go with the “normal characters”, there’s 62 of them.
Collision Constraints
If you assume a hashing function generates numbers pretty randomly spread throughout the number space available to it (which I will for this) there’s actually some pretty good math we can use to figure out how likely a collision will be. If you’re interested in where this comes from, check out the Birthday Paradox, which is nicely written up at Wikipedia. Using the formulas there you can calculate the probability of having 2 keys that collide, as a function of how many things you’re trying to insert, and the size of the overall hash space.
Putting it all together
First, figure out how many items you want to be able to store. (for me, 20,000 is a high estimate). Second, figure out how comfortable you are with having some keys collide. 50/50 odds? (0.5) 1/1000 chance? (0.001) I’m actually pretty ok having a very small number of collisions – I’m going to use 0.99, a 99% chance that SOMETHING will collide. (That’s still going to be a small number, less than a 100% chance that anything at all will collide, let alone more than one.)
I sketched up a little script for this article (which you can grab from my git repo. It’s pretty self-documenting, so I’ll let it speak for itself.
The goal is, given our constraints, and the fact that we need to use only the characters 0 .. 9, a .. z, A .. Z, (a) how many of those characters do we need, and (b) given that it probably won’t be an exact fit, what will our collision probability end up being?
my ($items, $probability) = (0,0);
GetOptions("items=i" => \$items, "probability=f" => \$probability);
printf("Trying to store %d items with a %0.5f chance of collision\n", $items, $probability);
# solve the birthday paradox in terms of 'how big the range should be'
# http://en.wikipedia.org/wiki/Birthday_paradox#Calculating_the_probability => wolfram alpha, 'solve for d'
my $max = -1*(($items - 1)*$items)/(2 * log(1-$probability));
print "To do that, we'd need to be working in the range 1:$max\n";
# compare that back to the original formula from Wikipedia and make sure that worked
my $calculated_prob = get_probability($max, $items);
printf("probability %0.10f should match your requested probability of %0.10f, or something went wrong.\n", $calculated_prob, $probability);
# so it does, cool
# how many bits would it take to represent $max?
my $frac_bits = log($max)/log(2);
my $real_bits = int($frac_bits)+1;
printf("This can be represented by %0.2f bits (%d)\n", $frac_bits, $real_bits);
# ok, so how about encoding those into URI's? We can use 0-9, a-z and A-Z, which gives 62 "digits"
# aka base62. $max in base62 can be calculated like we did "how many base2 digits were needed"
my $base62_digits = int(log($max)/log(62))+1;
print "Using 0..9, a..z and A..Z we can represent each object with $base62_digits digits\n";
# ok, if we're using 5 digits, what's our actual "space" and what's the probability of a collision?
my $newmax = 62**$base62_digits - 1;
# which is actually how many bits?
my $newbits = int(log($newmax)/log(2));
printf("Given that we'll have to use %d digits, (%d bits), the real probability of a collision is %0.10f\n", $base62_digits, $newbits, get_probability($newmax, $items));
sub get_probability {
my($max, $items) = @_;
return 1 - (($max - 1)/$max)**(($items*($items-1))/2);
}
The most mysterious parts of this are probably the formulas. The one in the get_probability subroutine is transcribed right from the Wikipedia page, but the other one is the same formula, solved for a different value. In general, if you need to do this, WolframAlpha is a math nerd’s dream come true. I just asked it to “solve (the equation) for d” and got the new formula I needed.
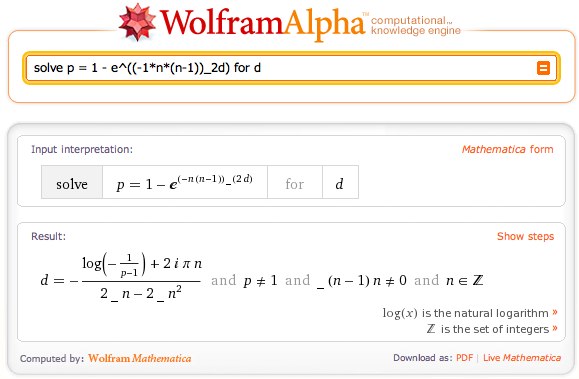
The solution actually comes from “show your steps” – I can find an intermediate form that’s easier to represent in a non-math-centric programming language. (I’m sure you can do imaginary numbers in perl, but it was kind of outside the scope of my plans for this evening.)
Here’s the formula I ended up using:
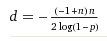
Here’s a few sample runs of the script:
First, using my personal constraints for this project:
$ ./hashspace_model -i 20000 -p 0.99
Trying to store 20000 items with a 0.99000 chance of collision
To do that, we'd need to be working in the range 1:43427276.7179157
probability 0.9900000006 should match your requested probability of 0.9900000000, or something went wrong.
This can be represented by 25.37 bits (26)
Using 0..9, a..z and A..Z we can represent each object with 5 digits
Given that we'll have to use 5 digits, (29 bits), the real probability of a collision is 0.1961141788
Cool! So I said I’m ok with a 99% chance of a collision, and the algorithm figured out that in order to do that, I’d need to be using 5 digits of base62. And if I’m using 5 digits of base62, I get 3 more bits than I strictly “need”, which means I end up with only about a 1/5 chance of EVER getting a collision.
Let’s say I wanted to be more strict, and go “one in a million”.
$ ./hashspace_model -i 20000 -p 0.000001
Trying to store 20000 items with a 0.000001 chance of collision
To do that, we'd need to be working in the range 1:199989899999232
probability 0.0000009992 should match your requested probability of 0.0000010000, or something went wrong.
This can be represented by 47.51 bits (48)
Using 0..9, a..z and A..Z we can represent each object with 8 digits
Given that we'll have to use 8 digits, (47 bits), the real probability of a collision is 0.0000009103
In this case base62 comes pretty close to exactly the dimensions that we want, so we more or less get 1/1,000,000 on the nose with 8 digits.
If you grab the script to play with, you may need to tweak the printf’s and make sure they have enough resolution for the data you’re trying to examine.
Ok, so that tells us how bit our bitspace needs to be, but not how to get a hash, or how to do base62.
Hashing Function
I chose md5 because…. it seems to work fine. I’m sure there’s a better option, but this is working for now. However, md5 has a lot more bits available than I need. How to just steal a few of them?
First, you need to know how many bits you want. Thankfully, I know I want 29 bits (thanks, helper script!). I can extract 29 bits of information from it by making a “mask” of 29 1’s, which can be done easily like so:
my $mask = 2**29 - 1;
So, now I just need a raw integer slice of an md5, and do a “logical and” of that:
use Digest::MD5 qw(md5);
# unpack makes this back into an integer for us
# L == interpret the data as a 32 bit unsigned long.
# See 'perldoc -f pack' for a ton of other options
my $value = unpack("L", md5("the string we want"));
$value = $value & $mask;
Groovy. Now we know what number we want to represent, we need to actually represent that in this weird “base62” format.
The algorithm for converting to base(anything) is actually pretty easy. We’re used to thinking in base10, so I’ll show an example of running the algorithm to from and to base10, just so the flow is clear.
| 125 | Starting Value |
| 125 % 10 = 5 | Find the remainder when dividing by the "destination base." Keep "5" as the "new number" |
| 125 / 10 = 12 | Divide by the "destination base". This chops the number off the end that we just snagged as a remainder |
| 12 % 10 = 2 | Do it again with the result of the division. Stick the result to the front of number we're keeping track of (now 25) |
| 12 / 10 = 1 | And do the division again |
| 1 % 10 = 1 | Last remainder, glue to the front again, and we have the answer "125". (Back where we started.) |
| 1 / 10 = 0 | As soon as we get 0 from the division, our work here is done. |
Simple enough to understand in base10, but the exact same technique works when going from base10 to any other base (2 would work to convert to binary, we’re using 62, and if you could find enough characters, you could go to something crazy like base300 using the same idea.)
Here’s the source for it:
# even though they are letters we are using them here in the role of "digits"
my @digits = (0 .. 9, 'a' .. 'z', 'A' .. 'Z');
my %digits = map { $digits[$_] => $_ } 0 .. $#digits;
sub to_base {
my($base, $value) = @_;
die "base $base out of range 1-62" unless ($base > 0 && $base <= 62);
return $digits[0] if $value == 0;
my $rep = "";
while($value > 0) {
# prepend the "digit" we get when dividing by the base
$rep = $digits[$value % $base ] . $rep;
# then "shift right" the working value
$value = int( $value / $base );
}
return $rep;
}
sub from_base {
my($base, $rep) = @_;
die "base $base out of range 1-62" unless ($base > 0 && $base <= 62);
my $value = 0;
# this pattern grabs a character at a time, left to right
for ( $rep =~ /./g ) {
$value *= $base;
$value += $digits{$_};
}
return $value;
}
So there you have it. Provably optimal URI-compatible identifiers with 3 easy steps:
- Figure out what the constraints for your problem space are
- Grab enough bits from md5
- Convert to (and from) base62