
A previous post on this blog looked at Building a Multiplayer Game with API Gateway+Websockets, Go and DynamoDB.
The point of that article was to provide an end to end example of a how an app like that could work on the serverless stack, from a full working Vanilla Javascript frontend, Infrastructure as Code deployment, a Go on Lambda backend, and with state stored in DynamoDB. I intentionally chose a pretty simple application (that still actually worked – and still works right now – so it was reasonably easy to understand each layer.
I was very, very, very much not trying to say that ALL multiplayer games, or realtime applications, should use this stack!
A question arrives ✉️
A few weeks ago, I got a nice email from someone who I will heavily paraphrase here:
Thanks for writing the post. It’s being passed around the game company I work at to make the case that we don’t need server-based game backends. However, I see your example is really simple. Our game needs to work for hundreds of players, with a very complex game state that’s frequently updated. Can the serverless architecture work for those cases too?
This is a great followup. (Which very effectively nerdsniped me.)
Can you use a DynamoDB and Serverless backend for a serious, high-state, modern game, or is it only useful for incredibly simple rock-paper-scissors level games? What is the most complex game you can use it for?

Before I get into that, it’s worth noting that there are many useful applications which work at a similar level of complexity to the example in the last post. It would work equally well for basically any of the web-based apps used in most of our work on a daily basis, and a large number of games as well.
- Anything where you are storing leaderboards or achievements, or doing matchmaking
- Turn-based games
- Board or card games
- Near real-time business apps
- Chat or collaboration features
- Software update systems
- … or anything else which is not that state intensive
After I started working on this post, AWS posted an excellent article by Tim Bruce called Building a serverless multi-player game that scales. In it, Tim describes a “Simple Trivia Service” game, which is well worth looking at in depth. The example has single and multiplayer modes, matchmaking, leaderboards, logins, and more. It’s far closer to a ‘real’ backend than the example I featured in my last post.
What do most “state intensive” game servers look like today?
What does the backend for a modern AAA multiplayer title look like?
In 2018, Google launched a hosted service with a matching open source project for managing game servers. Their launch blog post summarizes the state of the art, as much as I can tell from outside the game industry, pretty well. Emphasis added:
Many of the popular fast-paced online multiplayer games such as competitive FPSs, MMOs and MOBAs require a dedicated game server — a full simulation of the game world — for players to connect to as they play within it. This dedicated game server is usually hosted somewhere on the internet to facilitate synchronizing the state of the game between players, but also to be the arbiter of truth for each client playing the game, which also has the benefit of safeguarding against players cheating. Dedicated game servers are stateful applications that retain the full game simulation in memory. But unlike other stateful applications, such as databases, they have a short lifetime (minutes or hours). Dedicated game servers also need a direct connection to a running game server process’s hosting IP and port, rather than relying on load balancers. These fast-paced games are extremely sensitive to latency, which a load balancer only adds more of. Also, because all the players connected to a single game server share the in-memory game simulation state at the same time, it’s just easier to connect them to the same machine.
This makes sense. These games are managing a ton of complex and rapidly changing state – and trying to read in updates from players, simulate the game, send state changes back out to players, and detect cheaters – all as fast as possible. Tiny differences in latency can make the game feel laggy. Lambda can perform well, but occasionally (especially with a cold start) it can easily take 10s or 100s of milliseconds. That’s probably not acceptable for something like a first person shooter.
There’s another factor, too. When you build a multiplayer game, there is a lot of overlap between building the game client, and building the game server – especially if you’re using a framework like Unreal or Unity, and extra-especially if you want to offer the ability for people to do local multiplayer, where one person is both playing the game and acting as the server.

Finally, it’s important to think about what the uptime implications are. Nobody loves a game crash, but they are just accepted in this world. They are not on the same scale as “risk of losing a bank transaction.” A friend who works in esports reported that crashes are common enough that they have a protocol and a euphemistic name for them.
“Sorry folks, We’re experiencing a game pause.”
And this makes sense – for a short running game, in a short running process, you’re probably far more likely to experience a software issue (which could hit on any stack) than you are to have a problem with the underlying physical or virtual infrastructure.
So, if it’s true that
- You get most of the game server ‘for free’ as part of writing your game
- You are willing to accept crashes and the loss of all of that state
- The amount of state you’re storing would be way too expensive to store durably at all, within your economic model
- Single millisecond latencies matter a great deal to the experience of your game, and lag is unacceptable
… then yeah, I’d probably use an instance-based game engine, at least for the core.
It’s probably still worth thinking about hybrid architectures 🤔
Modern games have a lot more going on than just the high state intensity stuff. There’s also:
- Chat outside of the game engine
- Lobby/Matchmaking features
- Authentication/Authorization
- Software/Patch/Asset distribution
- Analytics
- In-App Purchases
- Achievements/Game Items
- Player Profiles
… and more. Some of those capabilities you may get from other platforms, but the less insane request rate makes the serverless environment more feasible if it’s something you’d need to build.
So, a hybrid architecture might make sense – use serverless for those sorts of things, and drop into a ‘real’ server for the high state game play.
For game aspects like achievements and purchases, something with strong durability (like DynamoDB) is essential. Losing things you have earned or paid for is one of the worst customer experiences in gaming. (I will not soon forget having to explain to one of my kids that no, it’s not ok to throw a controller, 🎮 even if you did just get kicked out of a game right after you finally came in first, and no, you probably won’t get the XP for it.)
So … Where is the line? ✏️
If you’ve come with me so far, there are games where serverless is the obvious choice. In the example from the previous post, you can handle thousands of game rounds for less than the cheapest instance AWS offers, AND your game will be more scalable, secure, reliable, and more. So that’s the serverless zone.
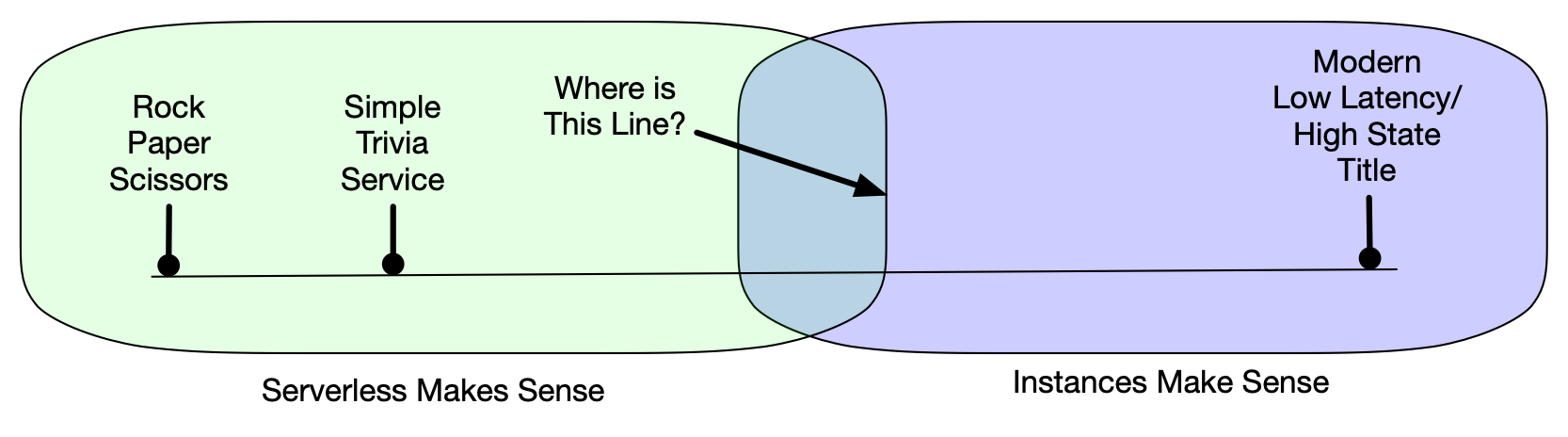
At the other end of the spectrum, there are the games that we’ve looked at likely never making sense with (at least this generation) of Serverless. The “Instances, yup, that checks out” zone.
So this got me curious – what is the boundary between those two zones? How might we find it?
I focused on two key questions:
- What kind of latency can I get from the serverless stack, and how predictable is it?
- At what level of state management does serverless become unaffordable?
My goal here is not to be comprehensive. There are too many variables between different protocols, instance types, networking configuration, CPU allocation, let alone the actual work that any real game might be trying to do, to worry too much about the details. For both the cost and latency numbers, this reasearch is basically one step beyond ‘back of the napkin’ math.
The Latency Question ⏲️
Test Setup
This test looks at latency, which is key for realtime interactivity. It’s important for getting your updates to the server in a timely manner and for having the game world represent the world you’re in as well. For this test, I looked at round trip time, how long it takes for me to send an event, have the backend process it, and get me the reply, because it roughly models the time it might take for some action I take in the game world to get to the other players.
To test this, I used websockets as a standard method, to reduce one of the variables across the different platforms.

I wrote a simple client that sends the current time (in nanoseconds) to a websocket echo server. When it gets the results back, it compares that to the current time, calculates the difference, and stores it. It does this in a single threaded way – waiting until it gets a response before it sends the next. The goal for this test was not to test concurrency, but to test backend to server request/response time.
This test then was run a few thousand times against 4 different versions of websocket echo:
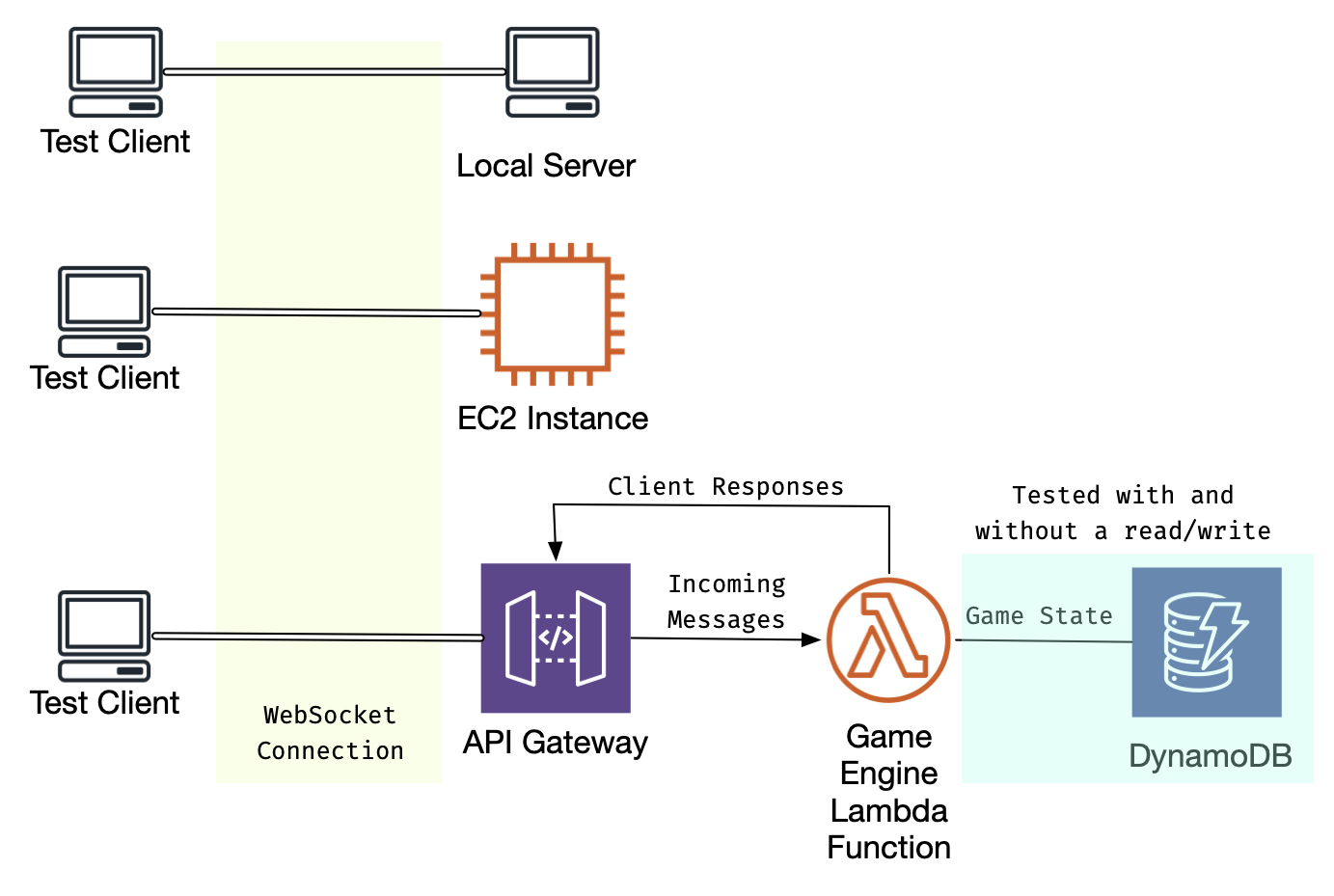
- Local: A client/server both running on the same host
- EC2: The same server running on an EC2 instance, tested from my standard home internet connection
- Serverless, Stateless: API Gateway and Lambda only, without storing the data
- Serverless, with DynamoDB: API Gateway and Lambda, with a read from and write to DynamoDB as part of each message.
Results
First, let’s look at the numerical results here. If you aren’t familiar with the ‘p’ notation, it’s percentile. You can think of p50 as “50% of requests were handled this fast or faster.” It’s critical to look at percentiles, rather than averages, for things like this where the data is not evenly distributed.
| Backend | p50 | p75 | p95 | p99 | Message Rate |
|---|---|---|---|---|---|
| Local Client/Server | 0.32ms | 0.35ms | 0.39ms | 0.43ms | 3076 messages/sec |
| EC2 Instance | 46ms | 48ms | 51ms | 54ms | 21.3 messages/sec |
| Serverless (No Dynamo) | 64ms | 69ms | 103ms | 1035ms | 10.9 messages/sec |
| Serverless (Dynamo r/w) | 77ms | 97ms | 269ms | 1175ms | 7.8 messages/sec |
The local numbers are interesting, because they provide the baseline of how long it takes to do all the inherent plumbing – generating the message, sending it on the network, processing it on the other end, and getting it back.

These charts are Kernel Density Estimations, which are a very useful way to visualize how values are distributed. They y axis (‘density’) translates to something like “the probability that a value in the sample will have a certain value.” They’re like smooth histograms, and I prefer them because they’re less susceptible to bin selection issues.
Zooming into the data from the local test, it’s very predictable, and it’s very fast. All the results are sub-millisecond, and they’re very tightly grouped.
Things get a lot more interesting when there’s a network hop involved.
First, EC2:

Since this is running the same code as the remote method, the round trip time is almost entirely the network round trip time from San Diego to Oregon.
Moving on to the serverless stack:

This chart just compares the two serverless methods, as their response time curves are similar enough to compare side by side. Making the two calls to dynamo has a suprisingly small impact to the p50 time, which is very close to the no-dynamo use case – but it raises the odds that things will be slower, and it raises the worst case execution time even further.
Seeing them all together in context is instructive. I’ve had to use a log scale here in the X axis to make the ec2 detail visible. Without it, due to the occasional long response times from the serverless stack, it just looks like a blip on the left side of the graph.

This is a boxplot which makes it clearer what’s happening. The EC2 row is centered around 46ms, with not much variability across requests. The two serverless rows have many outlier points in between 10^2 (100ms) and 10^3 (1 second), with clusters on the high side of 1 second, which I suspect are “cold starts”, when a new lambda is spun up to handle increases in traffic.
Takeaways
So, in a broad sense, these results are a big +1 for the serverless stack. To be able to get typical round trip times of around 100ms for working with a stateful backend with this little effort and operational overhead? Yes please.
However, if we’re talking about latency-sensitive gaming backends, it’s not as good. You really really wouldn’t want occasional 1 second freezes in the middle of an intense battle.
The long request times are avoidable, in part, by using Provisioned Concurrency, which specifically is built to prevent this. It keeps lambdas ready to go to handle your requests at whatever concurrency you desire – an interesting hybrid serverless and servery.
But even with those cold starts out of the picture, it’s hard to beat the instance here, especially when there is state to keep track of. The instance response time is dominated by networking limitations that are mostly about the speed of light.
Because in serverless, there are a few abstraction layers to get through – and the state needs to be stored persistently – it’s at a fundamental disadvantage here, which shows in the numbers. The ‘common’ (p50) response times for the dynamo interacting service are almost double the EC2 instance, and that is with extremely minimal state (one value read and written.)
So this is a good heuristic to walk away with. “If you need reliable, < 80ms response times for your application, serverless is probably not for you.”
The Cost Question 💵
In the original multiplayer game post, I showed that it was possible to run thousands of games, on an infrastructure that scales to zero costs when games were not running, and extremely high availability, for less cost than you could run even the cheapest AWS instance.
This post has hopefully already established that this wouldn’t be true if you were trying to use serverless to host the backend for Fortnite.
We’ve already looked at this question from the latency angle – what about costs? At what level does a multiplayer game become more expensive to host on servers versus serverless?
Here is a different way of looking at the architecture I used for the test here, and the points at which it can accrue AWS costs.
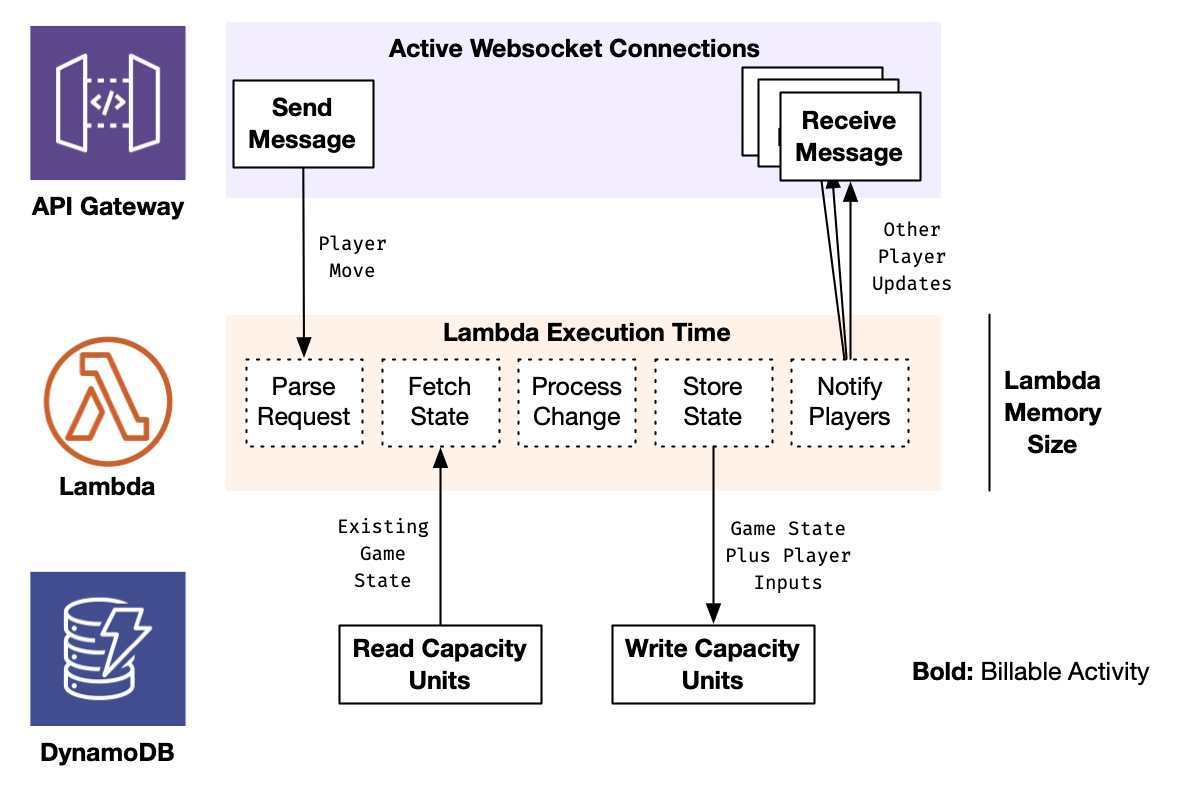
I’ll put in some cost numbers here – which represent the list prices, without any discounting or considering the free tier, in us-west-2, as of March 2021. There are some other costs that a real solution would have, like transfer costs, data storage costs, etc. I’m keeping them aside because they’d be fairly consistent regardless of the infrastructure used.
API Gateway charges for 2 things when you’re using websockets:
- A charge per connected client, based on the cumulative length of those connections ($0.25/million connection-minutes)
- A message send cost ($1/million 32kb chunks of message)
Lambda charges for:
- Each request handled ($0.20/Million requests)
- Per gig-second of memory used by executing processes ($0.0000166667)
DynamoDB charges can vary a lot by the feature you’re using, and by if you’re using on-demand or provisioned. (Which can be autoscaled, for an extra fun dimension.)
- On Demand
- $1.25/million write request units (1kb)
- $0.25/million read request units (1kb)
- Provisioned
- $0.00065 per Write Capacity Unit
- $0.00013 per Read Capacity Unit
That’s all hard to visualize, so I put together a basic calculator tuned for this use case.
There are also some buttons that set up example values for different scenarios. The default is based on the Rock/Paper/Scissors/Lizard/Spock example, and the ‘More Serious Game’ is based on more players, more state, and a higher request rate.
Presets:
... calculating ...
The difference between the three presets is pretty remarkable.
Rock Paper Scissors costs $0.38/thousand games. This is, still, hard to beat from an instance-only point of view.
This is extra compelling when you consider that the cost is the same if you play all thousand games at once – or spread them over a month. This is not something that’s possible with the instance paradgim. Costs scaling to zero is extra helpful, because you can deploy your infrastructure in many regions if you want, for availability and user performance.
The ‘more serious game’ setting comes in at $334/thousand games, three orders of magnitude higher. It’s helpful to compare it with the ’less disk state’ version, which only modifies how much state is read and written from DynamoDB – it is $43/thousand games. So almost 90% of the cost of this high frequency, very interactive game … is the state management.
This points at an interesting hybrid architecture possibility, e.g. in AWS’s Building a serverless multi-player game that scales they use Elasticache to be able to use Serverless to manage compute and user communications, but Elasticache (aka “RAM as a Service”) to handle the state more cost effectively than storing it durably on disk.
Conclusions
Where is the line between serverless and instances?
It seems instances still make sense for:
- Applications that need predictable, high volume and low latency responses (many requests/second, <100ms round trip time)
- Applications that need more than even a very small amount (10s of kilobytes) of state to make this type of high frequency decisions
Outside of that, especially when considering the total cost of ownership, security, maintainability, scaling to zero, and other nice factors of the broader serverless ecosystem – I would be considering it as the option to rule out first.
Cover Photo by Florian Olivo on Unsplash