
As previously discussed, this site is now being built with Hugo.
The final chapter in the Epic Tale of the Blog Migration is where the site is actually hosted.
These days I work with Amazon Web Services a lot, helping customers build scalable/available/“Cloudy” infrastructures for their projects, so it was a natural fit for me to use them for hosting the static site. There are many, many good ways to host static sites, but I’ve generally been a big fan of the features, price, performance and configurability of the Cloudfront / S3 teamup.
Here’s the overall architecture:
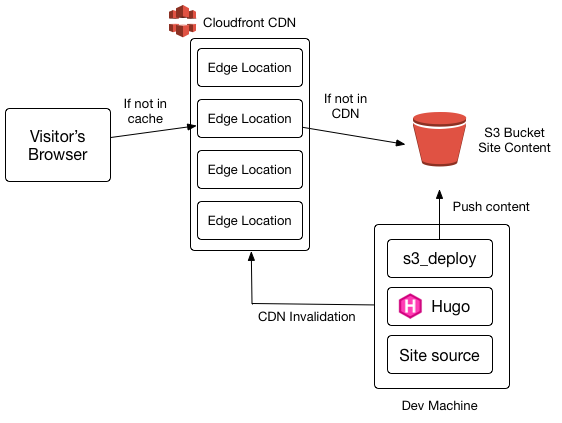
When the site’s updated, it’s pushed to an S3 bucket.
When a visitor goes to serialized.net, they’re directed to a cloudfront edge location that’s close to them from a latency perspective.
If the CDN location has the content in cache, and it hasn’t expired, it’s served. Otherwise, it fetches it from the S3 bucket and stores it.
As noted in the diagram, for maximum performance, we want things to be cached in people’s browsers as much as possible, and barring that, be in the CDN already.
Maximizing Browser Cacheability
To ensure that files are as likely as possible to end up in the browser cache if they’re needed, expiration information needs to be set.
This isn’t done by default with s3, you have to put a Cache Control meta tag on the object.
Enter s3deploy, from the lead maintainer of Hugo.
It has a few killer features: it parallelizes uploads, it’s much better at detecting which files do need to be uploaded, and it has a very handy way to manage setting cache attributes on files.
My .s3_deploy.yml file:
routes:
- route: "^.+\\.(js|css|svg|ttf|woff|eot|gif|pdf|jpeg|png|jpg)$"
# cache static assets for 20 years
headers:
Cache-Control: "max-age=630720000, no-transform, public"
gzip: true
- route: "^.+\\.(js|css)$"
# cache style, code for 1 hour
headers:
Cache-Control: "max-age=3600, no-transform, public"
gzip: true
- route: "^.+\\.(js|css|json)$"
# cache JSON (for JSON-feed) for 20m
headers:
Cache-Control: "max-age=1200, no-transform, public"
gzip: true
and it works:
$ http head https://serialized.net/images/hugo_nikola_process.svg
HTTP/1.1 200 OK
Cache-Control: max-age=630720000, no-transform, public
Browser cache is a dangerous tool to overuse; it can be very hard to ‘recall’ things cached at that layer. The best solution is to use disposable URL’s – encode some unique information in every reference to a page – but that’s not yet integrated into Hugo. It’s a known issue and there a number of workarounds.
For this blog, it’s simple enough that if I really need to change the content of a static asset I can tweak the references to it directly.
Maximize CDN Saturation
Just using Cloudfront at all gives you a ton of features out of the box that help with site performance.
- SSL certificates are free via ACM, and redirection to HTTPS is a single option
- HTTP/2 is easy to turn on, once you’ve got the free certificate
- IPv6 support
- Easily tunable cache minimums and behaviors
Beyond that, there are a lot of tactics to make sure your CDN is more likely to have the content in it.
I’m currently keeping it very simple:
- Set the default cache time to very long (1 week)
- Issue a full cache invalidation when I deploy new content
This is messy, but also useful for the early stages of working with a new site, where sweeping changes are more likely. The next step is to more tactically observe which files were actually updated, translate those to paths, and issue invalidations for those.
Cloudfront is easy to do a bulk invalidation for using the AWS CLI tools:
$ aws cloudfront create-invalidation --distribution-id MYDISTRIBUTION --paths '/*'
The pricing is very reasonable, too. You get 1,000 invalidations a month, and after that they cost $0.005 each. For a personal blog, if I make 100 changes a month I’m having a very prolific one, so it’s not an issue.
The next step is to either parse the output from s3_deploy, or submit a small patch, to analyze what was actually uploaded, and craft a more focused invalidation. This would make it more likely that edge locations that are accessed more rarely will have older content in cache.