
Update: This is way out of date. For anything current please see something like R.I. Pienaar’s seminal Simple Puppet Module Structure Redux.
I’ve been playing a lot with Puppet recently, and have been really focusing on getting a core set of modules in place. I found myself using a few module patterns over and over, so I thought I’d write them down and keep an updated list.
/base and /site
Our puppet modules are stored in 2 directories: /base and /site. Here are the purposes:
/base
The best way to think of what goes in /base is:
I should be able to (and should!) post my
/basetree to github or my blog, and it would be useful to other people.
Examples of things that might go into base are:
- virtuozzo
- nginx
- lighttpd
- perlbal
- debrepo
- rpmrepo
- openvpn
- mysql
- memcached
Essentially, the environments that make daemons or applications useable.
/site
Site should be
This should not be in any way useful (or safe to share) outside my company
Good examples might be:
mywebappmystatshudmymonitoringsystem
Module Design
Any functionality we want to do on a server can more or less be defined as:
I want to set up some applications and an environment in a certain way, so that it does what I want
Sample application: mywebapp
So, for example, if we wanted to build an mywebapp module, we’d need certain things to make that work.
Let’s assume that we need
- lighttpd installed and configured in a certain way
- apache installed and configured in a certain way
- some perl libraries installed
- some cron jobs set up
and so on.
The obvious way
The way I started out solving these sorts of problems turns out to not scale all that well. As I started a module (to solve a specific problem) I would just start listing out the puppet resources it would need.
mywebapp/manifests/init.pp
package { "lighttpd": ensure => installed }
service { "lighttpd": ensure => running, enabled => true }
package { "lib-catalyst-rest-perl": ensure => installed }
package { "apache2": ensure => installed }
service { "apache2": ....
and so on.
This breaks down in several ways.
Things can only be defined once in puppet
First, puppet only lets us define a resource once. So if we decide we want a new tool that needs the package lib-catalyst-rest-perl installed, or needs to use apache to host some stats HUD,
we’d have a problem.
statshud/manifests/init.pp
...
package { "apache2": ensure => installed }
...
Puppet will freak.
Puppet::Parser::AST::Resource failed with error ArgumentError: Duplicate definition: Package[apache2] is already defined in file statshub/manifests/init.pp at line 1; cannot redefine at statshub/manifests/init.pp:2 on node mondrian
Things would get repeated a lot
As a practical example, I refer you to the our lighttpd config.
It has an SSL config file, in which we find this little gem:
ssl.cipher-list = "DHE-RSA-AES256-SHA DHE-RSA-AES128-SHA EDH-RSA-DES-CBC3-SHA
AES256-SHA AES128-SHA DES-CBC3-SHA DES-CBC3-MD5 RC4-SHA RC4-MD5"
Neat! This implements the current best practices for what ciphers we should accept.
So having this in a base/ module, which is used by everything that needs to spin up a lighttpd, means that all my stuff will be running in the safest way I know how to run it.
The alternative is not very pleasant: I’d need to copy and paste this block in every one of my modules that used lighttpd. I’d need to keep it updated in each one of those files if and when a cipher turns out to be insecure.
Similarly, I can consolidate a lot of intelligence like this:
- making sure log rotation is correct
- making sure compression cache files are cleaned
- making sure monit is configured to restart it if it dies
- making sure file permissions are set up right
- ....
and, should we learn something New And Improved about any of these things, viola, all our useage of that module gets improved.
As an added benefit, this style of consolidation maps onto the way Puppet itself is going. Much like Perl has the CPAN, Puppet Modules will be getting some new features that allow them to be centralized. Soon we will be able to get “the puppet mysql module” rather than “some guy’s cloned module from a cloned module on github”.
Module Patterns
Because of the above threats and virtues, we want to push as much functionality as we can into base modules.
Basic Design
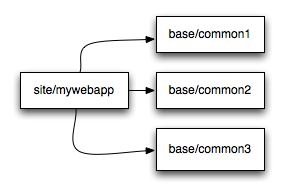
So how this looks in practice in puppet-speak:
mywebapp/manifests/init.pp
// configure lighttpd module
include lighttpd
// configure apache module
include apache
// configure mysql module
include mysql
// set up crons
cron {
command => "...."
}
Configuring other Classes
Ok, great, I’ve shipped all that intelligence to another module. But how do I make it work the way I want it to?
Well, we want to configure other classes. There are 3 basic methods to configure a class:
- Create subclasses and only include one or some of them
- Create 'defines' that we use from inside classes
- Set variables before you include it
Technique #1: Create subclasses and only include one or some of them
I’ll keep this one simple:
A lot of the time there are several distinct modes you might want to use an app in. For example, there’s a big difference between
include mysql
and
include mysql::server
Technique #2: Create ‘defines’ that we use from inside classes
This technique is the most commonly used one. Many of the application and daemon classes we want to configure have lots of “parts” that can be enabled. Some examples:
- monit config chunks
- apache/lighttpd/nginx sites
- subversion repos
These are best handled with defines. A good full-strength version of this is in our monit config:
define conf ( $source = '', $content = '' ) {
if $source != '' {
file { "/etc/monit.d/$name":
notify => Service["monit"],
source => $source,
mode => 644,
owner => root,
group => root,
}
} else {
file { "/etc/monit.d/$name":
notify => Service["monit"],
content => $content,
mode => 644,
owner => root,
group => root,
}
}
}
Notable features:
define conf ( $source = '', $content = '' )
This is useful because we can define a config file via either source or content.
I can call this from another module like:
include monit::common
monit::common::conf { "lighttpd-monit": source => "puppet:///lighttpd/lighthttpd-monitrc" }
or, if I wanted to template it:
include monit::common
monit::common::conf { "apache2": content => template("apache2/apache2-monitrc.erb") }
There’s no reason for us not to actually help people out and write common configs for them. This is easy with extra defines.
define simple_service ($pidname = $name) {
file { "/etc/monit.d/$name":
notify => Service["monit"],
content => template("monit/simple_service.erb"),
mode => 644,
owner => root,
group => root,
}
}
include monit::common
monit::common::simple_service { "apache2": pidname => "apache2" }
Technique #3: Set variables before you include the class
A good example might be for the mywebapp, I only want apache2 to be listening to the lo loopback interface. This would be a dumb default behavior if someone just did
include apache2
I would probably want it listening on all the public interfaces, by default.
So I can specify configuration variables:
In
site/mywebapp/manifests/init.pp
// we only want to have apache2 listening on the loopback
$apache2_interface = "lo"
include apache2
Then, in
base/apache2/manifests/init.pp
// if someone set this variable before they included our class, use it
if($apache2_interface) {
$interface = $apache2_interface
} else {
// by default use '*' which means listen on all interfaces
$interface = "*"
}
I like the idea of a consistent prefixing of configuration variables – for example, all config variables for module ‘foo’ would be ‘$foo_….’
Sometimes including a class doesn’t make sense unless we have some variable defined at all – there’s no reasonable default. Let’s say we’re configuring our local syslog – the server we syslog to. Without defining that, it doesn’t make sense to include the module.
We get this pretty much for free, actually. If you specify in your documentation:
You must specify a value for
$syslog_serverbefore including this module
base/syslog-client/manifests/init.pp
file { "/etc/syslog.conf":
content => template(syslog-client/syslog.conf.erb),
}
base/syslog-client/templates/syslog.conf.erb
#
# Remote Logging
#
destination d_remote {
tcp("<%= syslog_server %>", port(514));
};
So if someone tries to
include syslog-client
without defining that variable, puppet will error for you.
Failed to parse template syslog.conf.erb: Could not find value for 'syslog_server'
Conclusions
I’ll keep this page updated as more useful patterns emerge.
Thinking about decomposing modules by /base and /site is a powerful model already, as it helps develop new variants on ideas in a really rapid way with little to no copy and paste.
I’ve found that my site modules are often in the 4-7 lines long range, and I automatically get a lot of my hard-earned “best ways to do things” along for the ride.
And since I’m not the only one making things around here, everyone else saves time (and avoids some n00b mistakes) by being able to develop things more quickly as well.