
If you got here via a link to the slides
Please check out the full git repository for the presentation notebook as well as other example notebooks.
https://github.com/jbarratt/ipython_notebook_presentation/tree/linuxcon
What is the notebook?
A "browser-based interactive computing environment"
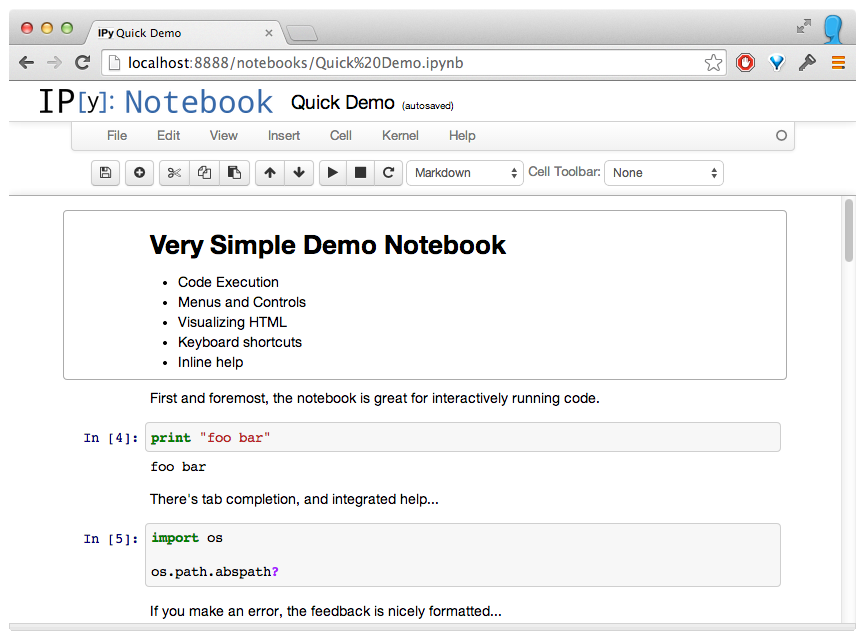
Why are we talking about it today?
- Extremely useful tool, but not well enough known outside Academia/Science.
- Makes the (powerful) python data/science/module ecosystem even more powerful
- If you code, (even not in python), sysadmin, write documentation, blog, do any analysis or visualization, you might get a lot out of the notebook.
Why are you talking about it today?
I fell in love.
Apologies to my beautiful baby daughter for photoshopping her out
Why It's Great
These attributes will come up over and over as we explore this tool.
"Literate"
The other attributes will be clear, but a word on Literate (apologies to Knuth for the oversimplification)
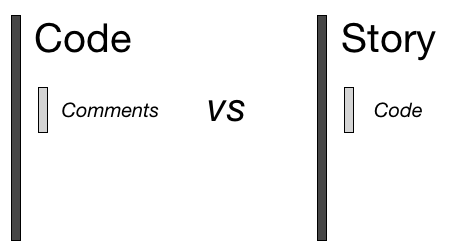
This is a big part of where the title comes from: it's about the story more than the software. (Because of inline output, Notebook may even be 'SuperLiterate'.)
Update: IPython's founder, @fperez_org kindly pointed me to a blog post of his; they prefer the term Literate Computing.
Enough Meta: Let's Install It.
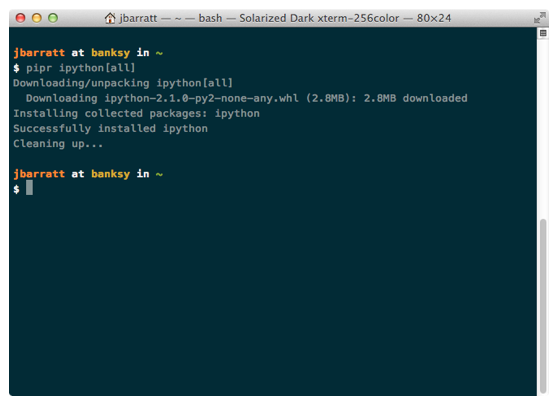
pip install ipython[all]? That was easy.*
*Dependencies can be painful, YMMV.
Run 'ipython notebook'
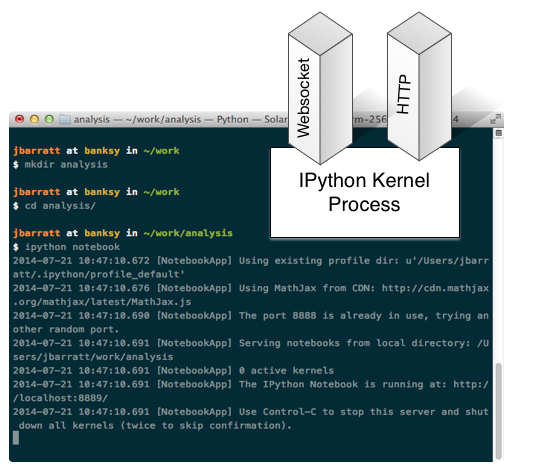
Clarification: As @fperez_org pointed out, the kernel actually only speaks zeromq, the notebook process handles browser communications.
Browser Launches
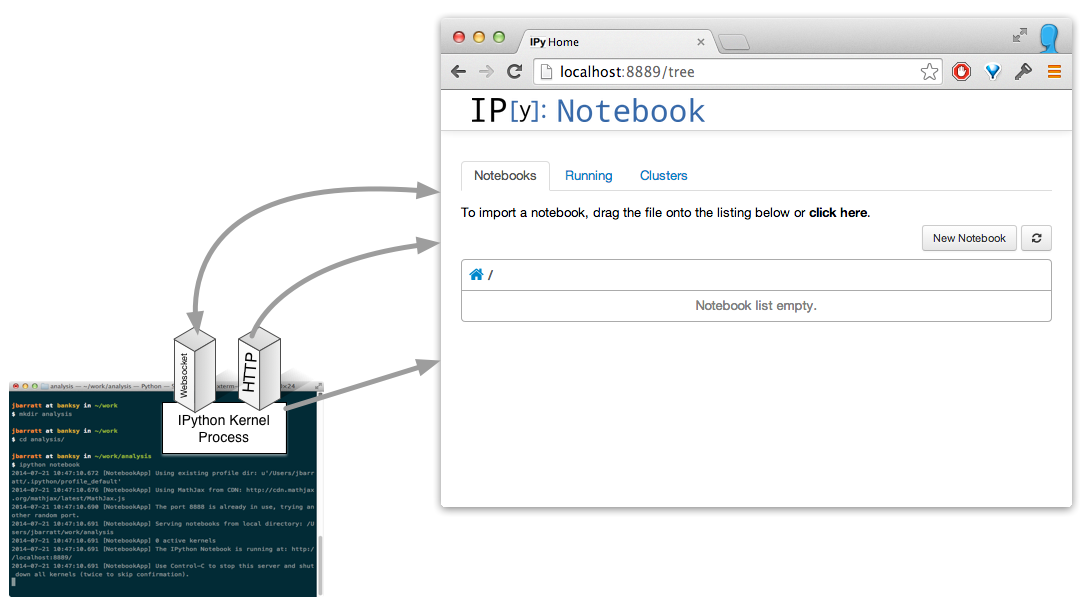
Build a notebook
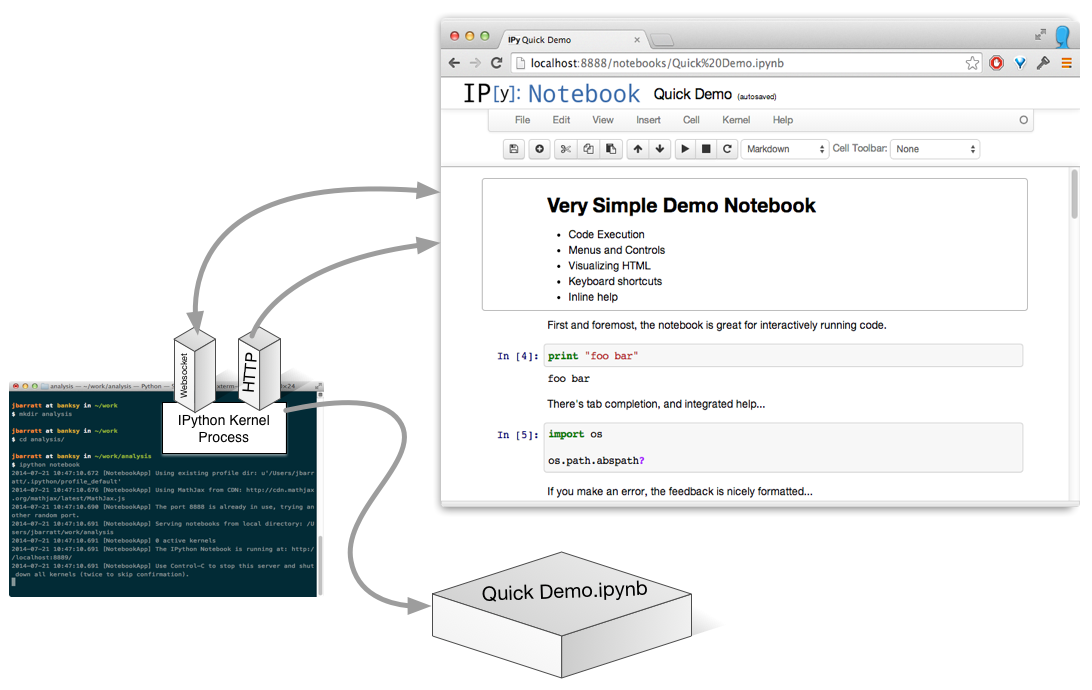
(Actually, it's a process per open notebook.)
Run A Cell
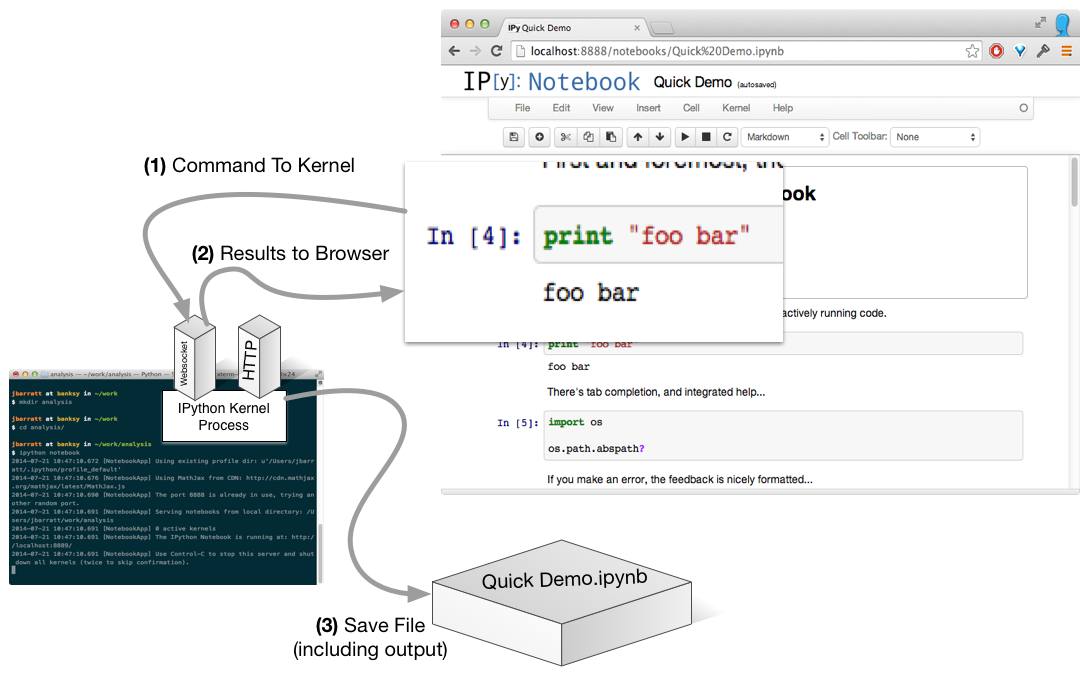
No Need To Be Local...
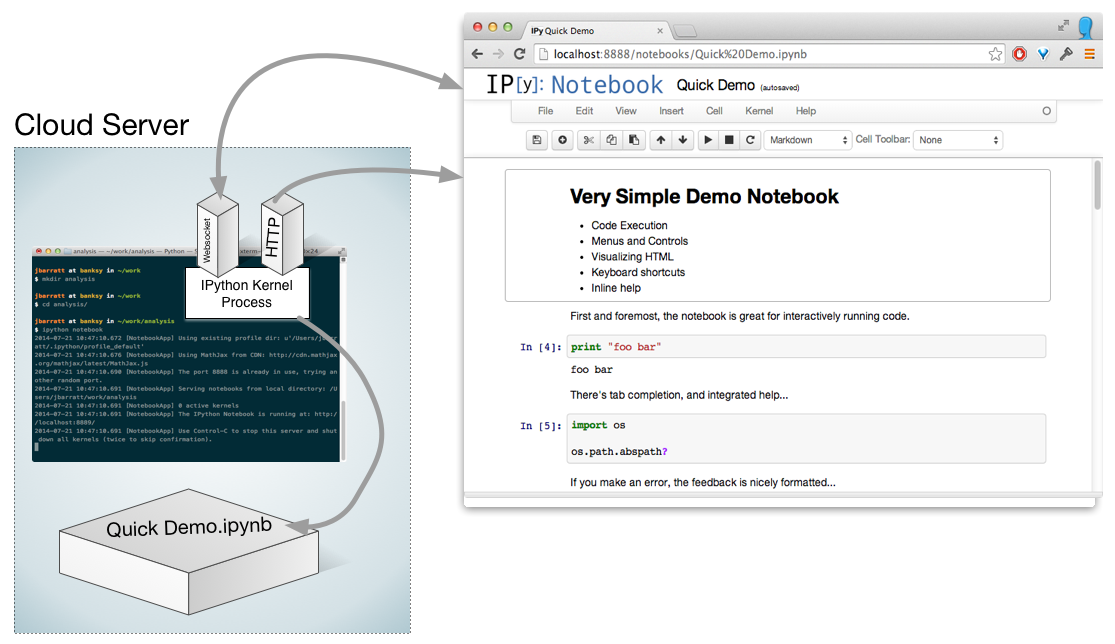
Demo Time

Notebook Workflows: The Big Picture
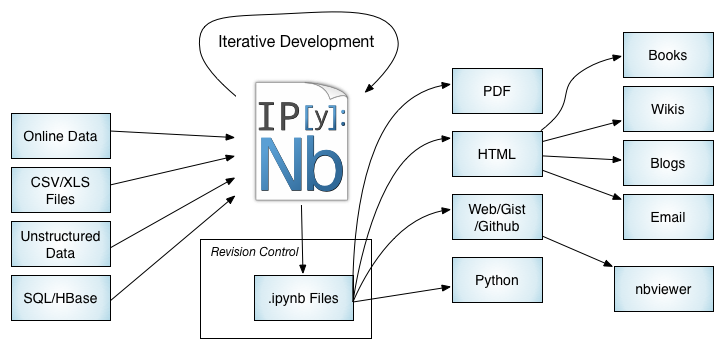
Not covered today but cool; clustering capabilities
How I Fell: Report Workflow v1
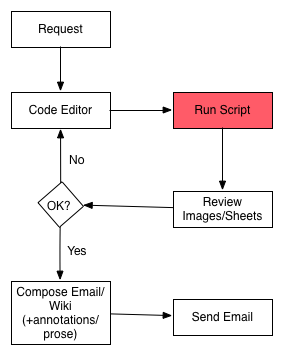
Problems:
- slow (read whole data file each time, lots of context switching)
- version controlled analysis, but not commentary, difficult to 'go back to'
- Automating requires non-trivial additional dev
Report Workflow now()
Speedups primarily from no context switching, interactivity, and reusable data loading.
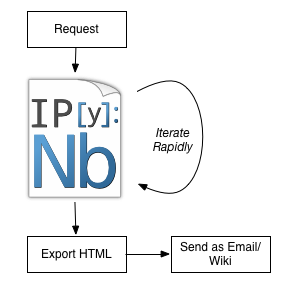

Reproducible, literate, annotatable, auditable.
Iterative Coding Example
"What are the most popular links being tweeted about #linuxcon?"
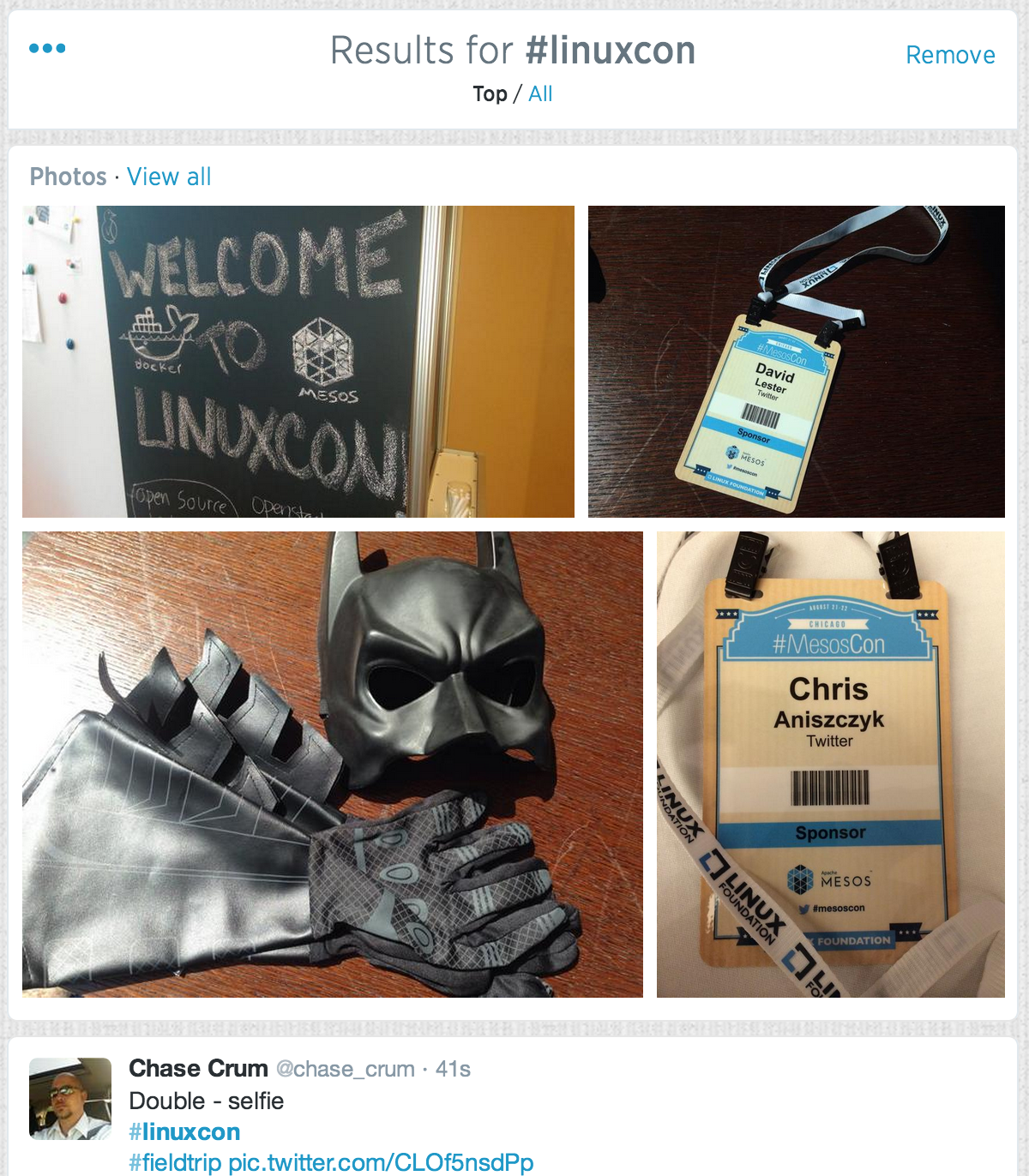
Let's start here
This (very solid) book is written largely with Notebook, and you can download the .ipynb files!

Interactive Example: Sign in
import json
import twitter
creds = json.load(open('/Users/jbarratt/.twitter.json'))
auth = twitter.oauth.OAuth(creds['access_token'],
creds['access_token_secret'],
creds['api_key'],
creds['api_secret'])
twitter_api = twitter.Twitter(auth=auth)
Interactive Example: Search for '#linuxcon'
search_results = twitter_api.search.tweets(q='#linuxcon', count=5000)
statuses = search_results['statuses']
print len(statuses)
# Original source for this loop:
# http://nbviewer.ipython.org/github/ptwobrussell/Mining-the-Social-Web-2nd-Edition/blob/master/ipynb/Chapter%201%20-%20Mining%20Twitter.ipynb
for _ in range(5):
try:
next_results = search_results['search_metadata']['next_results']
except KeyError, e: # No more results when next_results doesn't exist
break
kwargs = dict([ kv.split('=') for kv in next_results[1:].split("&") ])
search_results = twitter_api.search.tweets(**kwargs)
statuses += search_results['statuses']
print len(statuses)
Useful things to note
- Now we have a
statuseslist that's stored in our kernel. No hitting twitter rate limits. - I got that code from the mining the social web book, but I have no idea what to do next. We can explore.
Interactive Example: Inspect Results
# We know the results are in 'statuses', let's peek at one.
print json.dumps(statuses[1], indent=1)
Interactive Example: Link Extraction Attempt
import re # important note; this is common practice in notebooks, but violates PEP8
# "Imports are always put at the top of the file, just after any
# module comments and docstrings, and before module globals and constants."
# Yes, this is a terrible way to find URL-like strings.
re.findall(r'(https?://\S*)', statuses[0]['text'])
That looks plausible. Let's try applying that to all our results.
urls = []
for status in statuses:
urls += re.findall(r'(https?://\S*)', status['text'])
urls[0:10]
Huh, not great, if we use the text it looks like things get truncated. (\u2026 is … in unicode, what you see when a tweet trails off.)
Looking at the JSON again, it looks like a lot of these have ['entities']['urls'][(list)]['expanded_url'], let's try for those.
Interactive Example: Link Extraction Take Two
urls = []
for status in statuses:
try:
urls += [x['expanded_url'] for x in status['entities']['urls']]
except:
pass
urls[0:5]
Great! No more unicode weirdness. But, those shortened links are still redirects. Can we resolve them?
Interactive Example: Redirect Resolution
import requests
rv = requests.get('http://bit.ly/1vjbwEV')
rv.url
Handy. Turns out if you get something with requests you can just access the .url property and find what it got after follwing all the redirects.
Interactive Example: Counting URL's
from collections import Counter
import requests
# collections.Counter is a handy way to find 'Top N'
popular = Counter()
# Don't need to look up the same short link twice.
cache = {}
for url in urls:
if url in cache:
popular[cache[url]] += 1
else:
try:
rv = requests.get(url)
# resolve the original URL
cache[url] = rv.url
popular[rv.url] += 1
except:
# ignore anything bad that happens
pass
Interactive Example: Results
popular.most_common(10)
Why was that cool?
- Interactive & Exploratory.
- Scroll back up, re-review JSON, go another route
- Cached all the things
- Not hitting twitter a bunch (rate limits, etc)
- Static data set (not changing every time you run the code)
- Can even keep developing while on conference wifi (oohhhhhh)
- Easy to keep around as a log for future experiments
- Easy to take that learning and 'bake' it into something more permanent
The "IPython" in "IPython Notebook"`: Interactive Python

The Future
Skills port to the REPL
$ ipython
Python 2.7.6 (default, Jan 28 2014, 10:24:42)
Type "copyright", "credits" or "license" for more information.
IPython 3.0.0-dev -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: import webbrowser
In [2]: webbrowser.
webbrowser.BackgroundBrowser webbrowser.MacOSX webbrowser.open_new_tab
webbrowser.BaseBrowser webbrowser.MacOSXOSAScript webbrowser.os
webbrowser.Chrome webbrowser.Mozilla webbrowser.register
webbrowser.Chromium webbrowser.Netscape webbrowser.register_X_browsers
webbrowser.Elinks webbrowser.Opera webbrowser.shlex
webbrowser.Error webbrowser.UnixBrowser webbrowser.stat
webbrowser.Galeon webbrowser.get webbrowser.subprocess
webbrowser.GenericBrowser webbrowser.main webbrowser.sys
webbrowser.Grail webbrowser.open webbrowser.time
webbrowser.Konqueror webbrowser.open_new
Interactive Gotcha: Single Namespace
As you recall:
So what happens when you do...
x = 5
x
# I ran this cell a few times
x += 1
x
IPython Magic: Development Powertools
Which method is faster?
import random, string
# make a big list of random strings
words = [''.join(random.choice(string.ascii_uppercase) for _ in range(6)) for _ in range(1000)]
# Plan A: turn them all into lowercase with a list comprehension
def listcomp_lower(words):
return [w.lower() for w in words]
# Plan B: Start with a list, and word by word append the lowercase versions
def append_lower(words):
new = []
for w in words:
new.append(w.lower())
return new
# %timeit is IPython Magic to do a quick benchmark
%timeit append_lower(words)
%timeit listcomp_lower(words)
%lsmagic
Don't Panic
%%writefile?
%writefile [-a] filename
Write the contents of the cell to a file.
Exporting
ipynb format is clean, readable JSON, which inlines any output results, including base64'd images.
...
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Magic can be magical"
]
},
...
Great Notebook Use Cases
There are many use cases where the notebook makes a lot of sense to use. Here are a few illustrated examples:
- Code Mentorship
- Documentation/Runbooks
- Data Normalization (+ Inline Error Resolution)
- Data Analysis, Portland Example
- Web Logs
- Blogging
- Wiki'ing...
We won't go into them all for time, but a few highlights:
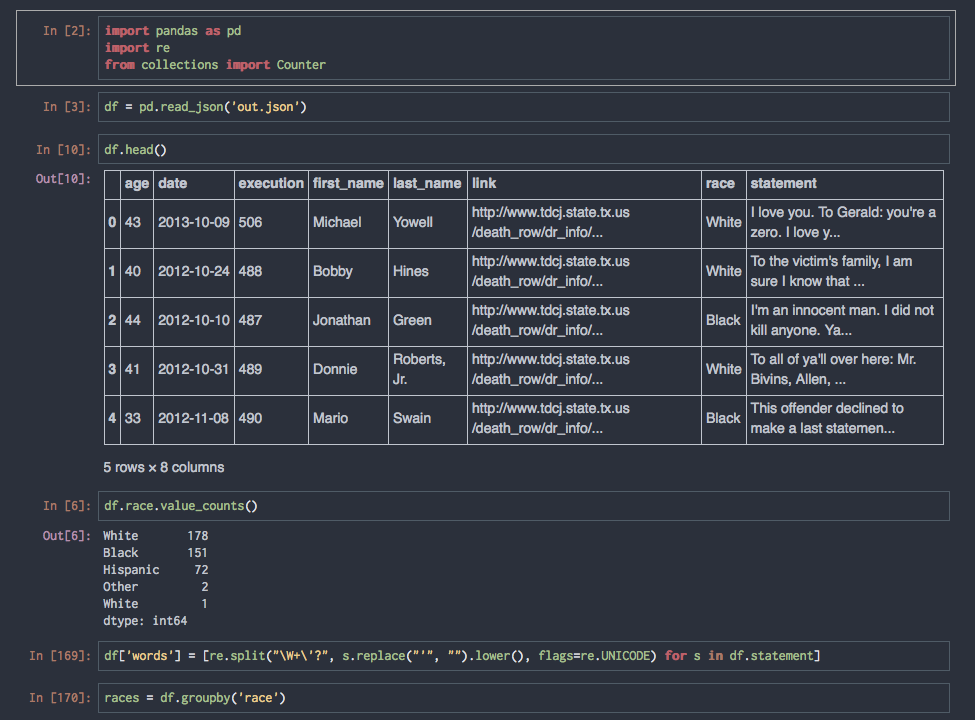
Use Case: Data Analysis
This is the gateway drug that gets many people into IPython Notebook. It's the real sweet spot between what makes Python great (pandas, scikit*, numpy, matplotlib, etc) and IPython Notebook great (Literate, Visual, Interactive, Iterative.)

Did I permanenently ruin your ability to hear the term 'big data' without thinking of this? You're welcome.
Use Case: Code Mentorship

Because you can't always pair...
Use Case: Documentation & Runbooks

Use Case: Wiki Publishing
Also can work for HTML emails, etc.
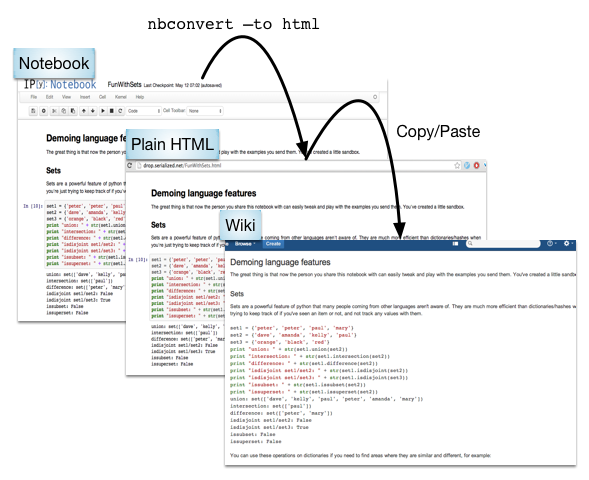
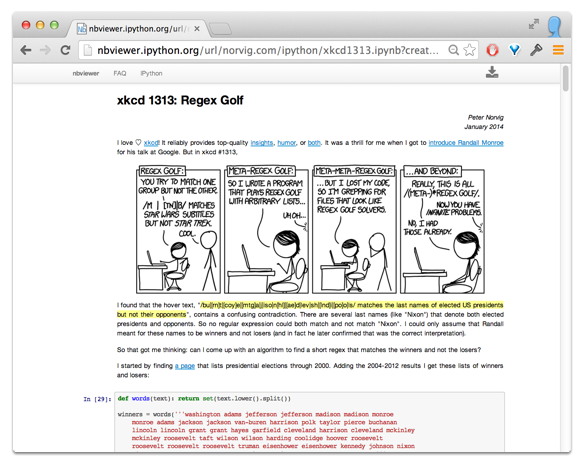
Clearing up the clutter
Lots of the slides had more code than we might want in a report; several approaches. It's on the notebook roadmap to add an 'official' way to do this.
%runmagic runs another notebook, pulling variables in- Move code to a local module (
ipython nbconvert --to python& refactor) or build a real module (Tip:%load_ext autoreload; %autoreload 2or%aimport mymodule) - Use a custom output template
- Easiest: Hide cells with a
custom.css. (Annoying caveat!)
/* Boss Mode */
div.input {
display: none;
}
div.output_prompt {
display: none;
}
div.output_text {
display: none;
}
Boss Mode HTML -> PDF Output

Customized Displays
Hey, we have HTML to play with! There are many ways to display prettier things inline.
- ipy_table does nice HTML Table display of list/tab data which isn't worth putting into pandas.
- IPython Display System covers many more capabilities in detail
Simple Custom HTML:
from IPython.core.display import HTML
def foo():
raw_html = "<h1>Yah, rendered HTML</h1>"
return HTML(raw_html)
Rich Objects
You can also define additional __repr__()-type methods on custom objects.
This has all kinds of fun possibilities.
_repr_html_(), svg, png, jpeg, html, javascript, latex.
class FancyText(object):
def __init__(self, text):
self.text = text
def _repr_html_(self):
""" Use some fancy CSS3 styling when we return this """
style=("text-shadow: 0 1px 0 #ccc,0 2px 0 #c9c9c9,0 3px 0 #bbb,"
"0 4px 0 #b9b9b9,0 5px 0 #aaa,0 6px 1px rgba(0,0,0,.1)")
return '<h1 style="{}">{}</h1>'.format(style, self.text)
FancyText("Hello #linuxcon!")
Automated Testing
Many options for testing, nothing too formal yet. These could easily be run by Travis/Jenkins/...
$ ./checkipnb.py xkcd1313.ipynb
running xkcd1313.ipynb
.........
FAILURE:
def test1():
assert subparts('^it$') == {'^', 'i', 't', '$', '^i', 'it', 't$', '^it', 'it$', '^it$'}
test1()
-----
raised:
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-11-a4492b0ec0d5> in <module>()
---> 26 test1()
<ipython-input-11-a4492b0ec0d5> in test1()
22 assert words('This is a TEST this is') == {'this', 'is', 'a', 'test'}
---> 23 assert lines('Testing / 1 2 3 / Testing over') == {'TESTING', '1 2 3', 'TESTING OVER'}
NameError: global name 'lines' is not defined
.............
ran notebook
ran 22 cells
1 cells raised exceptions
IPython (& Notebook) Customization
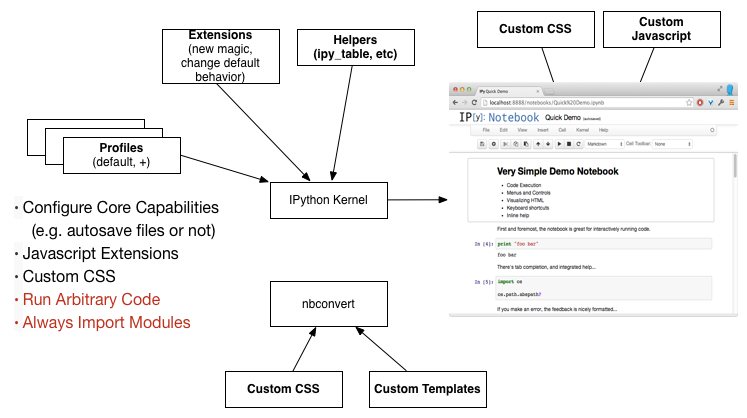
See more on Profiles, Javascript Extensions, IPython Extensions, and nbconvert Templates
profile = !ipython locate profile
print profile
custom_js = profile[0] + "/static/custom/custom.js"
print custom_js
!head $custom_js
Thankfully you can organize them in unique files, and just require them in custom.js
$([IPython.events]).on('app_initialized.NotebookApp', function(){
require(['/static/custom/clean_start.js']);
require(['/static/custom/styling/css-selector/main.js']);
})
Javascript, Huh, What is it good for
Customizing the UI
IPython.toolbar.add_buttons_group([
{
id : 'toggle_codecells',
label : 'Toggle codecell display',
icon : 'icon-list-alt',
callback : toggle
}
]);
And more...
Turns out, a lot! You can execute anything you can run in an IPython Notebook cell.
IPython.notebook.kernel.execute("!rm -rf /")
Demo Of a less scary example
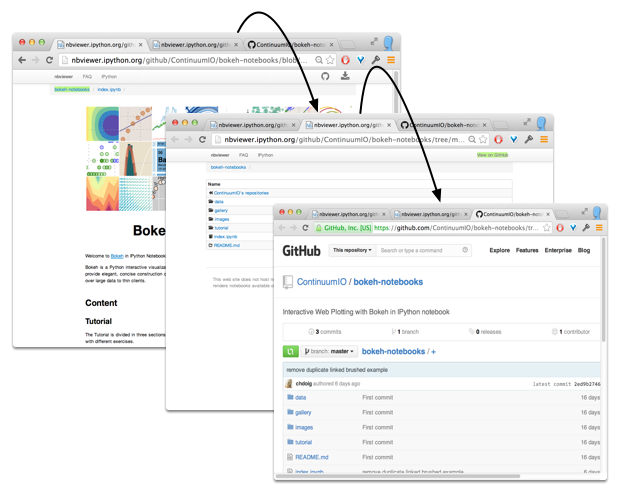
Sharing Notebooks
Personal Archive
One useful thing with having lots of notebooks around is high context sample code for solving future problems.
I wrote a simple tool (only works on OSX for now, yikes): nbgrep
!nbgrep seaborn
Oh, one more thing
IT CAME FROM INSIDE THE NOTEBOOK

- Highly technical decks can be created quickly
- Collaboration features are still quite useful
- Check It Out
Building slides
- Turn on the 'slideshow' cell toolbar
- Types:
- Slide: start a new slide
-: Continue a slide- Sub-Slide: Make a 'down' slide
- Fragment: Make a 'bullet' type incoming slide
- Skip: keep in the notebook, not the deck
- Notes: speaker notes
!ipython nbconvert Presentation.ipynb --to slides
Other Resources
Try It Online
Installing
$ pip install ipython[all](brew install python) OR- Anaconda OR
- docker-ipython
- Preloaded with lots of sometimes challenging-to-install packages like Pattern, NLTK, Pandas, NumPy, SciPy, Numba, Biopython...
Learning More
- Slides & example notebooks will be up on the OSCON site later.
- A Gallery of Interesting IPython Notebooks
- Extensions
- nbviewer (good way to discover organically)
- Pandas/numpy, Statsmodels, Matplotlib, bokeh, vincent, scikit-learn, scikit-image, .... (F150!)
- Talk to me! @jbarratt on twitter,
jbarratt@serialized.net
Credits
- Quill designed by Simple Icons from the Noun Project,
- Settings designed by Clément thorez from the Noun Project,
- Photo designed by Simple Icons from the Noun Project,
- Recurring Edit designed by Lemon Liu from the Noun Project
- Cover page texture from grungetextures via Flickr.